单机 Docker 部署 hadoop 集群实践
更新: 11/15/2024 字数: 0 字 时长: 0 分钟
环境搭建
环境搭建基于文章实践并编写。 容器使用docker网桥进行DNS解析,有可能在外部访问时会出现重定向到docker net的ip导致无法访问,如果有能力的通学可以使用内网ip重新映射。
镜像创建
这里我们配置一个免密登录的镜像,之后的所有节点都可以使用这个镜像
有能力的同学可以使用Dockerfile将以下内容总和构建镜像
1. docker先拉取ubuntu镜像
shell
docker pull ubuntu
2. 启动一个ubuntu镜像后安装vim,jdk,net-tool,ssh
shell
# 新建容器
docker run -it ubuntu:16.04 /bin/bash
# 查看容器id
docker ps
# 进入容器
docker exec 容器id /bin/bash
apt install openjdk-8-jdk
apt install vim
apt install net-tools
apt-get install openssh-server
apt-get install openssh-client3.配置免密登录
生成密钥并将公钥追加到 authorized_keys 文件中
shell
cd ~
ssh-keygen -t rsa -P ""
cat .ssh/id_rsa.pub >> .ssh/authorized_keys4. 启动ssh服务
设置启动容器的时候自动启动ssh。在~/.bashrc中加入以下内容
shell
service ssh start5.下载hadoop并解压到/usr/local/hadoop
shell
# 解压安装包到/usr/local
tar -zxvf hadoop-3.2.0.tar.gz -C /usr/local/
cd /usr/local/
# 将解压出的内容移动到hadoop文件夹
mv hadoop-3.2.0 hadoop6.在/etc/profile追加java和hadoop的环境变量:
shell
#java
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
#hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root7.进入目录/usr/local/hadoop/etc/hadoop后修改以下文件
shell
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=rootxml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop3/hadoop/tmp</value>
</property>
</configuration>xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>xml
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>shell
# Worker:这里写入的是所有节点的ip,因为之后使用网桥搭建,所以这里记录网桥内的DNS地址,这里只是使用一个datanode,所以如果服务器配置足够,可以多创建几个节点
master
slave8. 导出镜像
先退出容器,然后在宿主机执行,这里我们使用的是u-hadoop作为镜像名称
shell
docker commit -m "my haddop" 容器id u-hadoop搭建网桥
shell
docker network create --driver=bridge Hadoop
# 查看网桥
docker network ls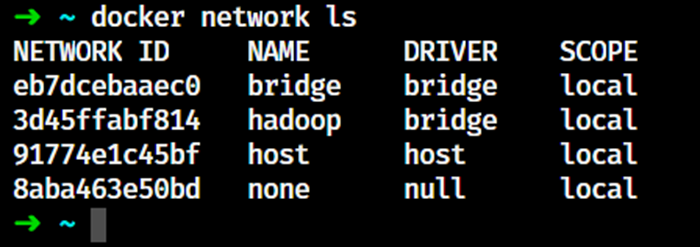
启动hadoop节点
1. 运行容器
创建master和slave的节点镜像,,匹配对应的网桥,在master中映射端口,方便后期直接通过网页访问。 如果想加入更多节点,可以在之前的Worker文件中加入host,同时多次运行slave镜像
shell
docker run -dit --network hadoop -h "master" --name "master" -p 9870:9870 -p 8088:8088 -p 9000:9000 u-hadoop /bin/bash
docker run -dit --network hadoop -h "slave" --name "slave" u-hadoop /bin/bash- --network:加入网桥
- -h:修改host
- -p:端口映射
2. 格式化hadoop
先进入master容器,然后执行内容
shell
cd /usr/local/hadoop/bin
./hadoop namenode -format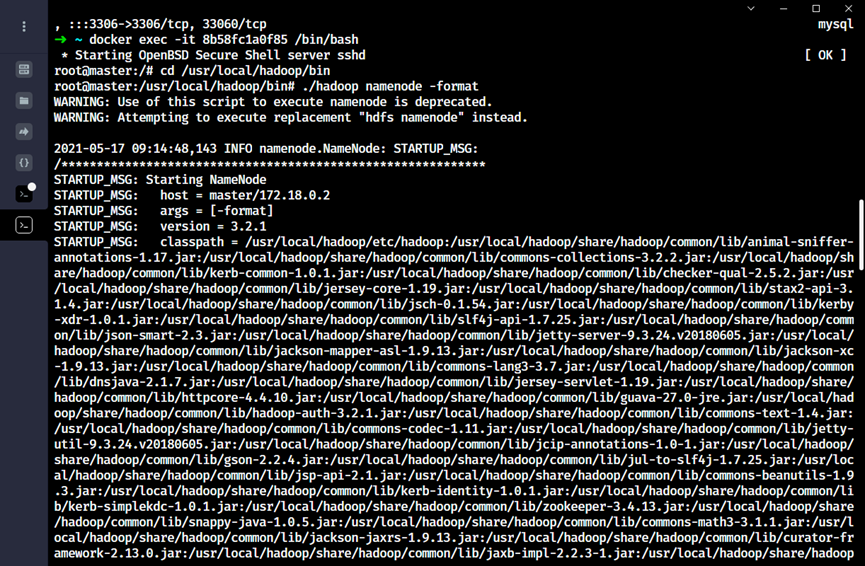
3. 启动hadoop
shell
cd /usr/local/hadoop/sbin/
./start-all.sh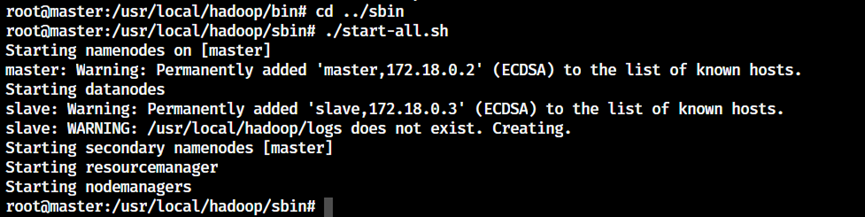
4. 查看分布式文件状态
shell
./hadoop dfsadmin -report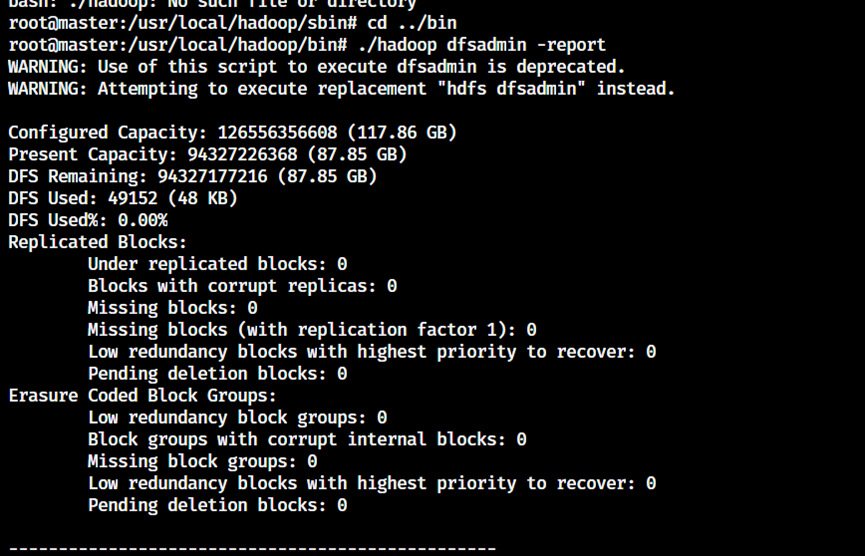
5. 访问hadoop相关端口
9807端口
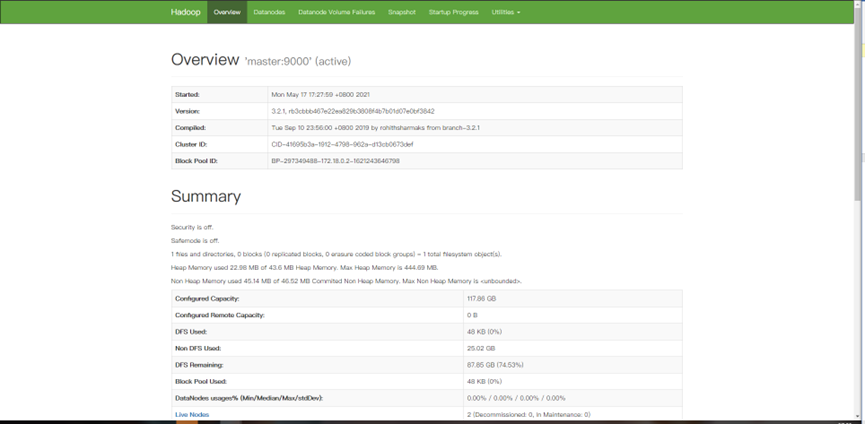
8088端口
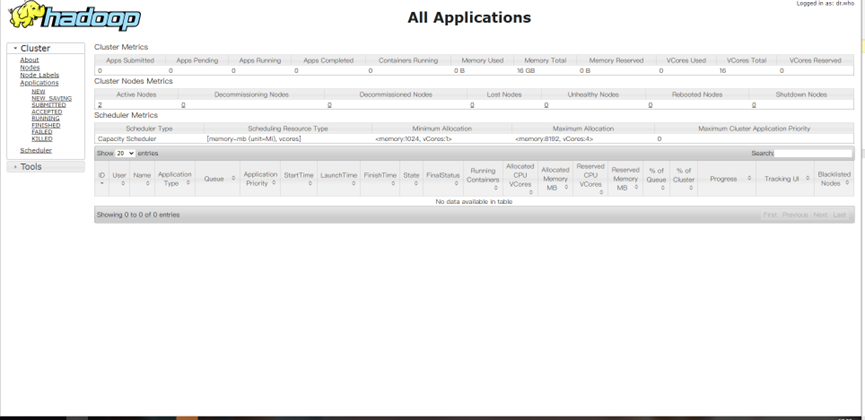
MapReduce 词频统计
1. hdfs上传文件
进入master容器后,在hdfs中创建文件夹
shell
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir /input
/usr/local/hadoop/testfile文件夹下创建wordfile1和wordfile2,里面存入一些英文句子
将文件拷入hdfs
shell
./bin/hdfs dfs -put testfile/wordfile1 /input/
./bin/hdfs dfs -put testfile/wordfile2 /input/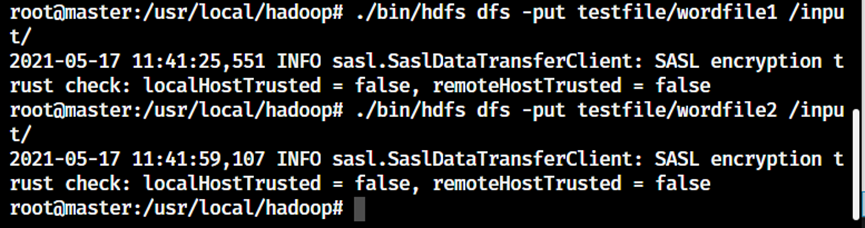
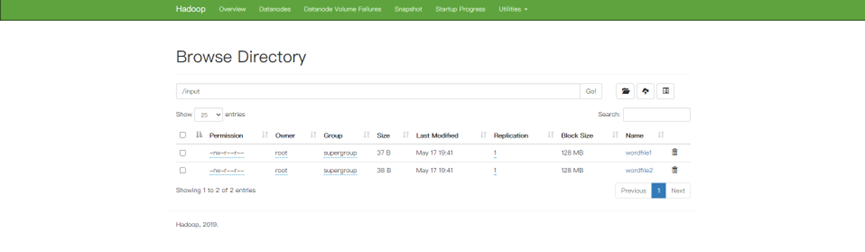
2. 本地编写程序
xml
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
java
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count"); //设置环境参数
job.setJarByClass(WordCount.class); //设置整个程序的类名
job.setMapperClass(WordCount.TokenizerMapper.class); //添加Mapper类
job.setReducerClass(WordCount.IntSumReducer.class); //添加Reducer类
job.setOutputKeyClass(Text.class); //设置输出类型
job.setOutputValueClass(IntWritable.class); //设置输出类型
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i])); //设置输入文件
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));//设置输出文件
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}3. 运行程序
将程序打成Jar包,然后上传到服务器中,然后复制到master容器中/usr/local/hadoop
shell
docker cp ./ WordCount-jar-with-dependencies.jar master:/usr/local/hadoop进入容器后,运行程序
shell
cd /usr/local/hadoop
./bin/hadoop jar ./WordCount-jar-with-dependencies.jar WordCount /input /output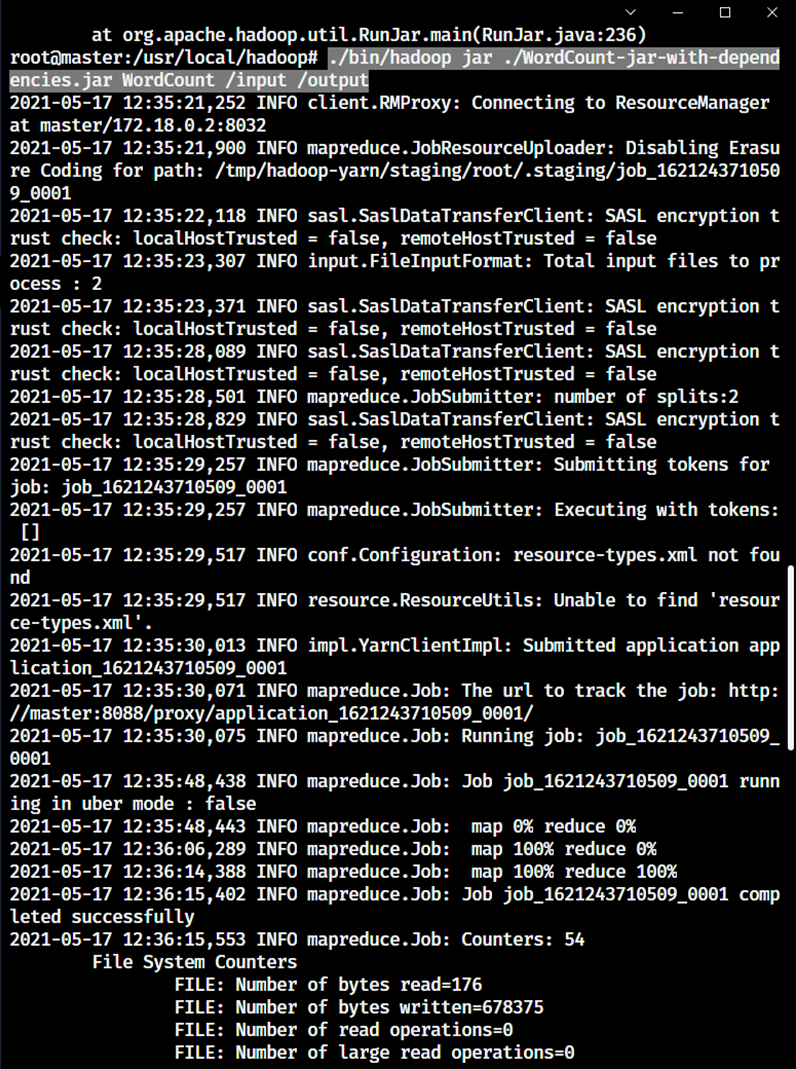
查看运行结果
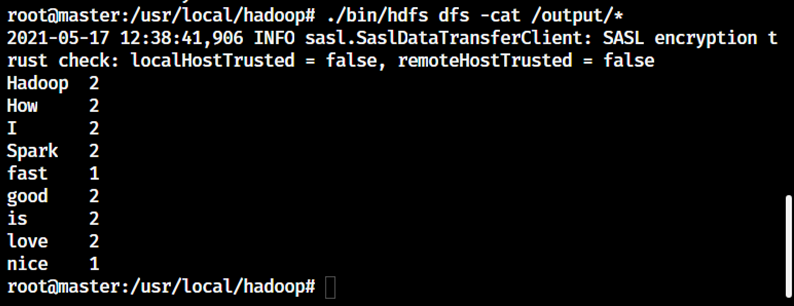
shell
./bin/hdfs dfs -cat /output/*